Java I/O 类库概况
Java 的 I/O 操作类在包 java.io 下,大概有将近 80 个类,但是这些类大概可以分成四组,分别是:
- 基于字节操作的 I/O 接口:InputStream 和 OutputStream
- 基于字符操作的 I/O 接口:Writer 和 Reader
- 基于磁盘操作的 I/O 接口:File
- 基于网络操作的 I/O 接口:Socket
字节与字符的转化接口
InputStreamReader
InputStreamReader 类是字节到字符的转化桥梁,InputStream 到 Reader 的过程要指定编码字符集,否则将采用操作系统默认字符集
StreamDecoder 正是完成字节到字符的解码的实现类
OutputStreamWriter
OutputStreamWriter 类完成,字符到字节的编码过程,由 StreamEncoder 完成编码过程
磁盘 I/O 工作机制

Java Socket 的工作机制
概念
Socket 这个概念没有对应到一个具体的实体,它是描述计算机之间完成相互通信一种抽象功能
打个比方,可以把 Socket 比作为两个城市之间的交通工具,有了它,就可以在城市之间来回穿梭;交通工具有多种,每种交通工具也有相应的交通规则
Socket 也一样,也有多种:大部分情况下我们使用的都是基于 TCP/IP 的流套接字,它是一种稳定的通信协议
建立通信链路 - client
当客户端要与服务端通信,客户端首先要创建一个 Socket 实例,操作系统将为这个 Socket 实例分配一个没有被使用的本地端口号,并创建一个包含本地和远程地址和端口号的套接字数据结构,这个数据结构将一直保存在系统中直到这个连接关闭
在创建 Socket 实例的构造函数正确返回之前,将要进行 TCP 的三次握手协议,TCP 握手协议完成后,Socket 实例对象将创建完成,否则将抛出 IOException 错误
建立通信链路 - server
与之对应的服务端将创建一个 ServerSocket 实例,ServerSocket 创建比较简单只要指定的端口号没有被占用,一般实例创建都会成功,同时操作系统也会为 ServerSocket 实例创建一个底层数据结构,这个数据结构中包含指定监听的端口号和包含监听地址的通配符,通常情况下都是“*”即监听所有地址
之后当调用 accept() 方法时,将进入阻塞状态,等待客户端的请求。当一个新的请求到来时,将为这个连接创建一个新的套接字数据结构,该套接字数据的信息包含的地址和端口信息正是请求源地址和端口
这个新创建的数据结构将会关联到 ServerSocket 实例的一个未完成的连接数据结构列表中,注意这时服务端与之对应的 Socket 实例并没有完成创建,而要等到与客户端的三次握手完成后,这个服务端的 Socket 实例才会返回,并将这个 Socket 实例对应的数据结构从未完成列表中移到已完成列表中
所以 ServerSocket 所关联的列表中每个数据结构,都代表与一个客户端的建立的 TCP 连接
数据传输
当连接已经建立成功,服务端和客户端都会拥有一个 Socket 实例,每个 Socket 实例都有一个 InputStream 和 OutputStream,正是通过这两个对象来交换数据
当 Socket 对象创建时,操作系统将会为 InputStream 和 OutputStream 分别分配一定大小的缓冲区,数据的写入和读取都是通过这个缓存区完成的
写入端将数据写到 OutputStream 对应的 SendQ 队列中,当队列填满时,数据将被发送到另一端 InputStream 的 RecvQ 队列中
NIO

channel
通道是对原 I/O 包中的流的模拟,到任何目的地(或来自任何地方)的所有数据都必须通过一个 Channel 对象
拿 NIO 与原来的 I/O 做个比较,通道就像是流。通道与流的不同之处在于通道是双向的,而流只是在一个方向上移动(一个流必须是 InputStream 或者 OutputStream 的子类), 而 通道 可以用于读、写或者同时用于读写
正如前面提到的,所有数据都通过 Buffer 对象来处理。您永远不会将字节直接写入通道中,相反,您是将数据写入包含一个或者多个字节的缓冲区。同样,您不会直接从通道中读取字节,而是将数据从通道读入缓冲区,再从缓冲区获取这个字节
selector
Selector 可以比作为一个车站的车辆运行调度系统,它将负责监控每辆车的当前运行状态:是已经出战还是在路上等等,也就是它可以轮询每个 Channel 的状态
buffer
Buffer 是一个对象, 它包含一些要写入或者刚读出的数据。 在 NIO 中加入 Buffer 对象,体现了新库与原 I/O 的一个重要区别。在面向流的 I/O 中,您将数据直接写入或者将数据直接读到 Stream 对象中。
在 NIO 库中,所有数据都是用缓冲区处理的:在读取数据时,它是直接读到缓冲区中的;在写入数据时,它是写入到缓冲区中的。任何时候访问 NIO 中的数据,您都是将它放到缓冲区中
缓冲区实质上是一个数组。通常它是一个字节数组,但是也可以使用其他种类的数组。但是一个缓冲区不 仅仅 是一个数组。缓冲区提供了对数据的结构化访问,而且还可以跟踪系统的读/写进程
1 | // io 与 nio 比较 |
1 | // copy file |
NIO 引入了 Channel、Buffer 和 Selector 就是想把这些信息具体化,让程序员有机会控制它们,如:当我们调用 write() 往 SendQ 写数据时,当一次写的数据超过 SendQ 长度时需要按照 SendQ 的长度进行分割,这个过程中需要有将用户空间数据和内核地址空间进行切换,而这个切换不是你可以控制的;而在 Buffer 中我们可以控制 Buffer 的 capacity,并且是否扩容以及如何扩容都可以控制
buffer 的状态变量
可以用三个值指定缓冲区在任意时刻的状态,这三个变量一起可以跟踪缓冲区的状态和它所包含的数据:
positionlimitcapacity
相关详细:NIO 入门
buffer 的访问方法
缓存区分配和包装
- ByteBuffer.allocate( 1024 ) : ByteBuffer
- ByteBuffer.wrap( new byte[1024] ) : ByteBuffer
读写
您可能需要将用户数据保存到磁盘。在这种情况下,您必须将这些数据直接放入缓冲区,然后用通道将缓冲区写入磁盘
或者,您可能想要从磁盘读取用户数据。在这种情况下,您要将数据从通道读到缓冲区中,然后检查缓冲区中的数据
- get()
- put()
缓存区分片
1 | buffer.position( 3 ); |
只读缓冲区
- byteByffer.asReadOnlyBuffer()
零拷贝
Java NIO 中提供的 FileChannel 拥有 transferTo() 和 transferFrom() 两个方法,可直接把 FileChannel() 中的数据拷贝到另外一个 Channel,或者直接把另外一个 Channel 中的数据拷贝到 FileChannel
该接口常被用于高效的网络/文件的数据传输和大文件拷贝:在操作系统支持的情况下,通过该方法传输数据并不需要将源数据从内核态拷贝到用户态,再从用户态拷贝到目标通道的内核态,同时也避免了两次用户态和内核态间的上下文切换,也即使用了“零拷贝”,所以其性能一般高于Java IO中提供的方法
1 | public class NIOClient { |
同步、异步、阻塞、非阻塞
同步与异步
所谓同步就是一个任务的完成需要依赖另外一个任务时,只有等待被依赖的任务完成后,依赖的任务才能算完成,这是一种可靠的任务序列:要么成功都成功,失败都失败,两个任务的状态可以保持一致
而异步是不需要等待被依赖的任务完成,只是通知被依赖的任务要完成什么工作,依赖的任务也立即执行,只要自己完成了整个任务就算完成了。至于被依赖的任务最终是否真正完成,依赖它的任务无法确定,所以它是不可靠的任务序列
我们可以用打电话和发短信来很好的比喻同步与异步操作
在设计到 IO 处理时通常都会遇到一个是同步还是异步的处理方式的选择问题。因为同步与异步的 I/O 处理方式对调用者的影响很大,在数据库产品中都会遇到这个问题。因为 I/O 操作通常是一个非常耗时的操作,在一个任务序列中 I/O 通常都是性能瓶颈。但是同步与异步的处理方式对程序的可靠性影响非常大,同步能够保证程序的可靠性,而异步可以提升程序的性能,必须在可靠性和性能之间做个平衡,没有完美的解决办法。
阻塞与非阻塞
阻塞与非阻塞主要是从 CPU 的消耗上来说的,阻塞就是 CPU 停下来等待一个慢的操作完成 CPU 才接着完成其它的事
非阻塞就是在这个慢的操作在执行时 CPU 去干其它别的事,等这个慢的操作完成时,CPU 再接着完成后续的操作
虽然表面上看非阻塞的方式可以明显的提高 CPU 的利用率,但是也带了另外一种后果就是系统的线程切换增加:增加的 CPU 使用时间能不能补偿系统的切换成本需要好好评估
两种的方式的组合
| 组合方式 | 性能分析 |
|---|---|
| 同步阻塞 | 最常用的一种用法,使用也是最简单的,但是 I/O 性能一般很差,CPU 大部分在空闲状态。 |
| 同步非阻塞 | 提升 I/O 性能的常用手段,就是将 I/O 的阻塞改成非阻塞方式,尤其在网络 I/O 是长连接,同时传输数据也不是很多的情况下,提升性能非常有效。这种方式通常能提升 I/O 性能,但是会增加 CPU 消耗,要考虑增加的 I/O 性能能不能补偿 CPU 的消耗,也就是系统的瓶颈是在 I/O 还是在 CPU 上。 |
| 异步阻塞 | 这种方式在分布式数据库中经常用到,例如在往一个分布式数据库中写一条记录,通常会有一份是同步阻塞的记录,而还有两至三份是备份记录会写到其它机器上,这些备份记录通常都是采用异步阻塞的方式写 I/O。 异步阻塞对网络 I/O 能够提升效率,尤其像上面这种同时写多份相同数据的情况。 |
| 异步非阻塞 | 这种组合方式用起来比较复杂,只有在一些非常复杂的分布式情况下使用,像集群之间的消息同步机制一般用这种 I/O 组合方式。如 Cassandra 的 Gossip 通信机制就是采用异步非阻塞的方式。 它适合同时要传多份相同的数据到集群中不同的机器,同时数据的传输量虽然不大,但是却非常频繁。这种网络 I/O 用这个方式性能能达到最高。 |
server和异步IO
server 实现
- Java I/O,单线程:循环处理请求——同一时间只能处理一个请求,等待I/O的过程浪费大量CPU资源,同时无法充分使用多CPU的优势
- Java I/O,多线程:为每个请求创建一个线程;为了防止连接请求过多,导致服务器创建的线程数过多,造成过多线程上下文切换的开销,可以通过线程池来限制创建的线程数
- Java NIO,单线程:经典 Reactor 模式——所有读/写请求以及对新连接请求的处理都在同一个线程中处理,无法充分利用多CPU的优势,同时读/写操作也会阻塞对新连接请求的处理
- Java NIO,多线程:多工作线程 Reactor 模式
- Java NIO,多线程:多 Reactor 模式
经典 Reactor 模式
在Reactor模式中,包含如下角色
- Reactor 将I/O事件发派给对应的Handler
- Acceptor 处理客户端连接请求
- Handlers 执行非阻塞读/写
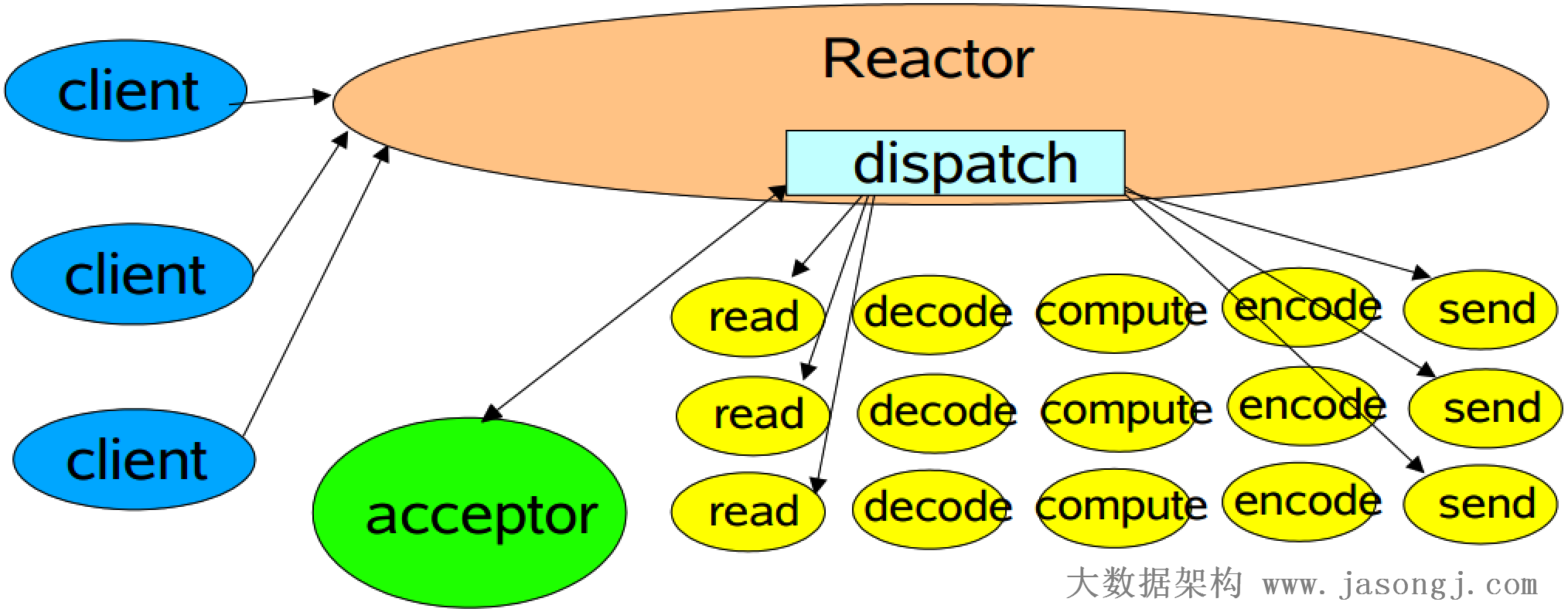
调用 Selector 的静态工厂创建一个选择器,创建一个服务端的 Channel 绑定到一个 Socket 对象,并把这个通信信道注册到选择器上,把这个通信信道设置为非阻塞模式
然后就可以调用 Selector 的 selectedKeys 方法来检查已经注册在这个选择器上的所有通信信道是否有需要的事件发生,如果有某个事件发生时,将会返回所有的 SelectionKey,通过这个对象 Channel 方法就可以取得这个通信信道对象从而可以读取通信的数据,而这里读取的数据是 Buffer,这个 Buffer 是我们可以控制的缓冲器
1 | public class NIOServer { |
从上示代码中可以看到,多个Channel可以注册到同一个Selector对象上,实现了一个线程同时监控多个请求状态(channel)
同时注册时需要指定它所关注的事件,例如上示代码中 socketServerChannel 对象只注册了 OP_ACCEPT 事件,而 socketChannel 对象只注册了 OP_READ 事件
selector.select() 是阻塞的,当有至少一个通道可用时该方法返回可用通道个数。同时该方法只捕获Channel注册时指定的所关注的事件
多工作线程Reactor模式
经典Reactor模式中,尽管一个线程可同时监控多个请求(channel),但是所有读/写请求以及对新连接请求的处理都在同一个线程中处理,无法充分利用多CPU的优势,同时读/写操作也会阻塞对新连接请求的处理;因此可以引入多线程,并行处理多个读/写操作
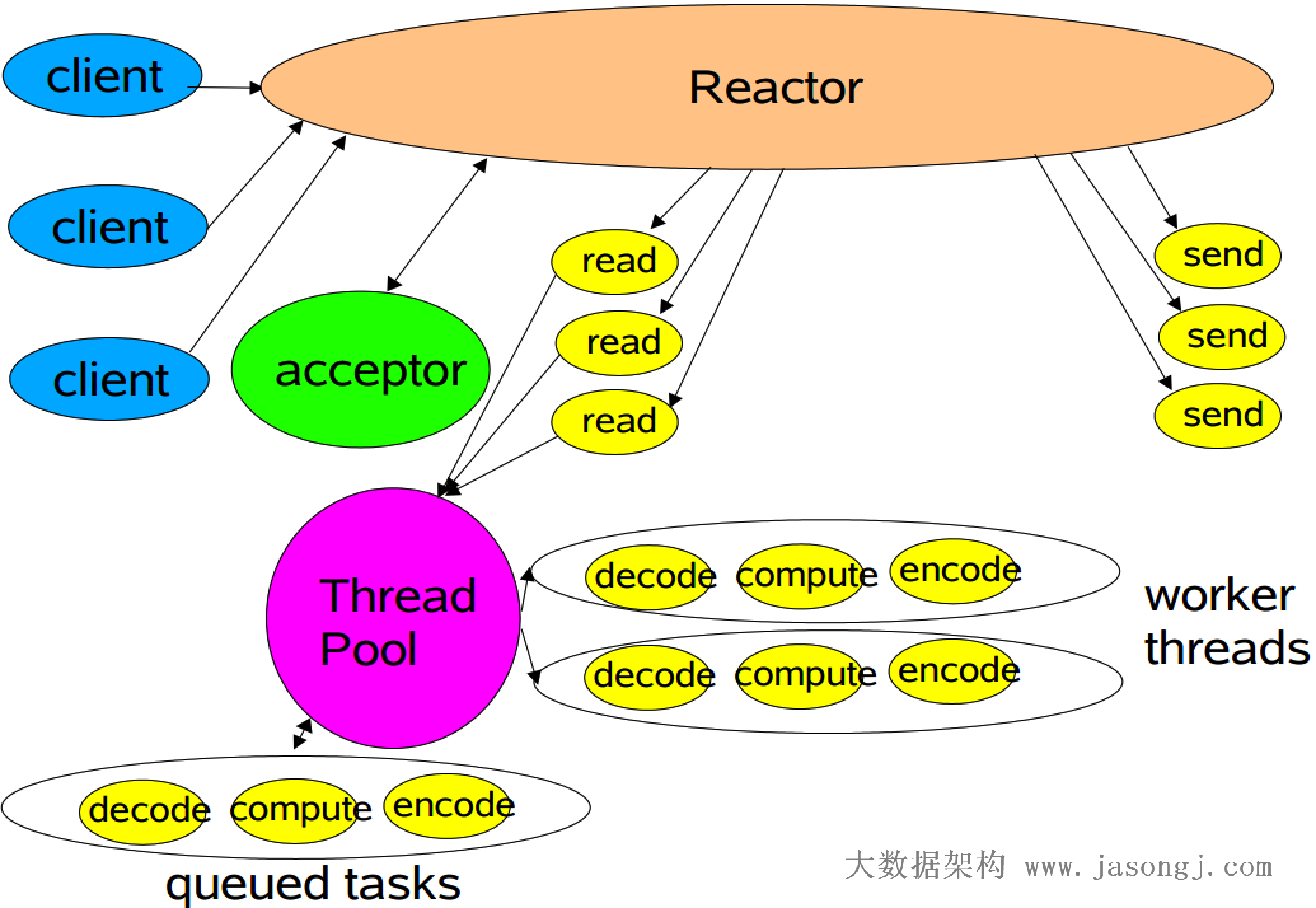
1 | public class NIOServer { |
从上示代码中可以看到,注册完 SocketChannel 的 OP_READ 事件后,可以对相应的 SelectionKey attach 一个对象(本例中 attach 了一个 Processor 对象,该对象处理读请求),并且在获取到可读事件后,可以取出该对象
注:attach对象及取出该对象是 NIO 提供的一种操作,但该操作并非 Reactor 模式的必要操作,本文使用它,只是为了方便演示NIO的接口
具体的读请求处理在如下所示的 Processor 类中。该类中设置了一个静态的线程池处理所有请求。而 process 方法并不直接处理 I/O 请求,而是把该 I/O 操作提交给上述线程池去处理,这样就充分利用了多线程的优势,同时将对新连接的处理和读/写操作的处理放在了不同的线程中,读/写操作不再阻塞对新连接请求的处理
1 | public class Processor { |
多Reactor
Netty中使用的Reactor模式,引入了多Reactor,也即一个主Reactor负责监控所有的连接请求,多个子Reactor负责监控并处理读/写请求,减轻了主Reactor的压力,降低了主Reactor压力太大而造成的延迟
并且每个子Reactor分别属于一个独立的线程,每个成功连接后的Channel的所有操作由同一个线程处理,这样保证了同一请求的所有状态和上下文在同一个线程中,避免了不必要的上下文切换,同时也方便了监控请求响应状态
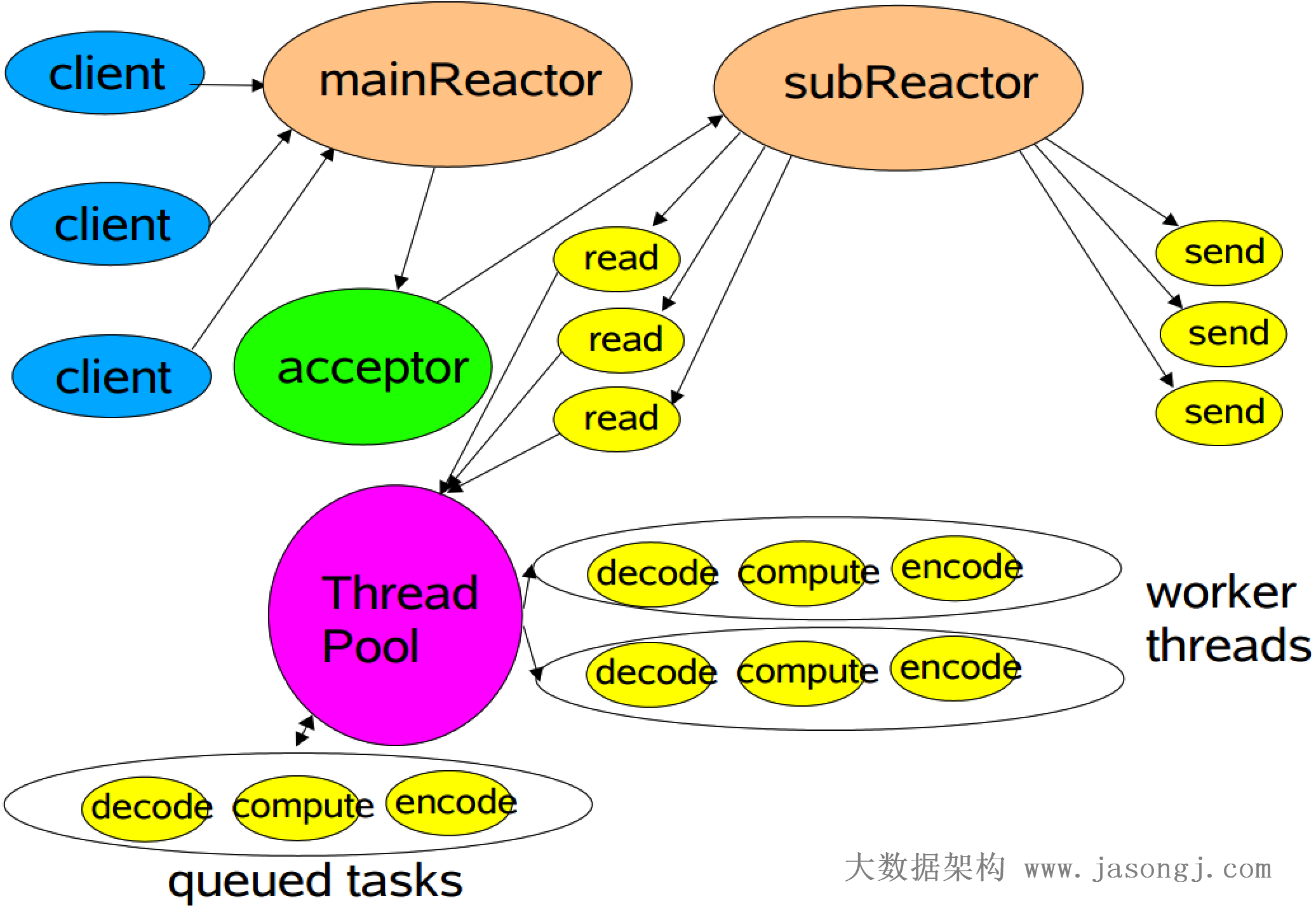
1 | public class NIOServer { |
如上代码所示,本文设置的子 Reactor 个数是当前机器可用核数的两倍(与 Netty 默认的子 Reactor 个数一致)
对于每个成功连接的 SocketChannel,通过 round robin 的方式交给不同的子 Reactor
子 Reactor 对 SocketChannel 的处理如下所示
1 | public class Processor { |
在Processor中,同样创建了一个静态的线程池,且线程池的大小为机器核数的两倍
每个Processor实例均包含一个Selector实例,同时每次获取Processor实例时均提交一个任务到该线程池,并且该任务正常情况下一直循环处理,不会停止
而提交给该Processor的SocketChannel通过在其Selector注册事件,加入到相应的任务中,由此实现了每个子Reactor包含一个Selector对象,并由一个独立的线程处理
I/O 调优
磁盘 I/O 优化
提升磁盘 I/O 性能通常的方法有:
- 增加缓存,减少磁盘访问次数
- 优化磁盘的管理系统,设计最优的磁盘访问策略,以及磁盘的寻址策略,这里是在底层操作系统层面考虑的。
- 设计合理的磁盘存储数据块,以及访问这些数据块的策略,这里是在应用层面考虑的。如我们可以给存放的数据设计索引,通过寻址索引来加快和减少磁盘的访问,还有可以采用异步和非阻塞的方式加快磁盘的访问效率。
- 应用合理的 RAID 策略提升磁盘 IO,每种 RAID 的区别我们可以用下表所示:
| 磁盘阵列 | 说明 |
|---|---|
| RAID 0 | 数据被平均写到多个磁盘阵列中,写数据和读数据都是并行的,所以磁盘的 IOPS 可以提高一倍。 |
| RAID 1 | RAID 1 的主要作用是能够提高数据的安全性,它将一份数据分别复制到多个磁盘阵列中。并不能提升 IOPS 但是相同的数据有多个备份。通常用于对数据安全性较高的场合中。 |
| RAID 5 | 这中设计方式是前两种的折中方式,它将数据平均写到所有磁盘阵列总数减一的磁盘中,往另外一个磁盘中写入这份数据的奇偶校验信息。如果其中一个磁盘损坏,可以通过其它磁盘的数据和这个数据的奇偶校验信息来恢复这份数据。 |
| RAID 0+1 | 如名字一样,就是根据数据的备份情况进行分组,一份数据同时写到多个备份磁盘分组中,同时多个分组也会并行读写。 |
网络 I/O 优化
网络 I/O 优化通常有一些基本处理原则:
- 一个是减少网络交互的次数:要减少网络交互的次数通常我们在需要网络交互的两端会设置缓存,比如 Oracle 的 JDBC 驱动程序,就提供了对查询的 SQL 结果的缓存,在客户端和数据库端都有,可以有效的减少对数据库的访问
- 除了设置缓存还有一个办法是,合并访问请求:如在查询数据库时,我们要查 10 个 id,我可以每次查一个 id,也可以一次查 10 个 id。再比如在访问一个页面时通过会有多个 js 或 css 的文件,我们可以将多个 js 文件合并在一个 HTTP 链接中,每个文件用逗号隔开,然后发送到后端 Web 服务器根据这个 URL 链接,再拆分出各个文件,然后打包再一并发回给前端浏览器。这些都是常用的减少网络 I/O 的办法
- 减少网络传输数据量的大小:减少网络数据量的办法通常是将数据压缩后再传输,如 HTTP 请求中,通常 Web 服务器将请求的 Web 页面 gzip 压缩后在传输给浏览器。还有就是通过设计简单的协议,尽量通过读取协议头来获取有用的价值信息。比如在代理程序设计时,有 4 层代理和 7 层代理都是来尽量避免要读取整个通信数据来取得需要的信息。
- 尽量减少编码:通常在网络 I/O 中数据传输都是以字节形式的,也就是通常要序列化。但是我们发送要传输的数据都是字符形式的,从字符到字节必须编码。但是这个编码过程是比较耗时的,所以在要经过网络 I/O 传输时,尽量直接以字节形式发送。也就是尽量提前将字符转化为字节,或者减少字符到字节的转化过程
- 根据应用场景设计合适的交互方式:主要包括同步与异步阻塞与非阻塞方式
参考资料